

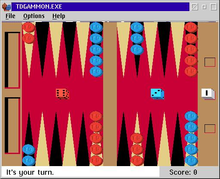
 OS/2 TD-Gammon game screenshot
OS/2 TD-Gammon game screenshotTD-Gammon was a computer backgammon program developed in 1992 by Gerald Tesauro at IBM's Thomas J. Watson Research Center. Its name comes from the fact that it is an artificial neural net trained by a form of temporal-difference learning, specifically TD-lambda.
TD-Gammon achieved a level of play just slightly below that of the top human backgammon players of the time. It explored strategies that humans had not pursued and led to advances in the theory of correct backgammon play.
Each turn while playing a game, TD-Gammon examines all possible legal moves and all their possible responses (two-ply look-ahead), feeds each resulting board position into its evaluation function, and chooses the move that leads to the board position that got the highest score. In this respect, TD-Gammon is no different than almost any other computer board-game program. TD-Gammon's innovation was in how it learned its evaluation function.
TD-Gammon's learning algorithm consists of updating the weights in its neural net after each turn to reduce the difference between its evaluation of previous turns' board positions and its evaluation of the present turn's board position - hence "temporal-difference learning". The score of any board position is a set of four numbers reflecting the program's estimate of the likelihood of each possible game result: White wins normally, Black wins normally, White wins a gammon, Black wins a gammon. For the final board position of the game, the algorithm compares with the actual result of the game rather than its own evaluation of the board position.
After each turn, each weight in the neural net gets updated according to the following rule:
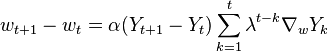
where:
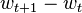 |
is the amount to change the weight from its value on the previous turn. |
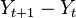 |
is the difference between the current and previous turn's board evaluations. |
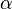 |
is a "learning rate" parameter. |
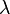 |
is a parameter that affects how much the present difference in board evaluations should feed back to previous estimates. 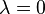 makes the program correct only the previous turn's estimate; makes the program correct only the previous turn's estimate; 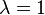 makes the program attempt to correct the estimates on all previous turns; and values of between 0 and 1 specify different rates at which the importance of older estimates should "decay" with time. makes the program attempt to correct the estimates on all previous turns; and values of between 0 and 1 specify different rates at which the importance of older estimates should "decay" with time. |
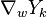 |
is the gradient of neural-network output with respect to weights: that is, how much changing the weight affects the output. |
Unlike previous neural-net backgammon programs such as Neurogammon (also written by Tesauro), where an expert trained the program by supplying the "correct" evaluation of each position, TD-Gammon was at first programmed "knowledge-free". In early experimentation, using only a raw board encoding with no human-designed features, TD-Gammon reached a level of play comparable to Neurogammon: that of an intermediate-level human backgammon player.
Even though TD-Gammon discovered insightful features on its own, Tesauro wondered if its play could be improved by using hand-designed features like Neurogammon's. Indeed, the self-training TD-Gammon with expert-designed features soon surpassed all previous computer backgammon programs. It stopped improving after about 1,500,000 games (self-play) using 80 hidden units.
TD-Gammon's exclusive training through self-play (rather than tutelage) enabled it to explore strategies that humans previously hadn't considered or had ruled out erroneously. Its success with unorthodox strategies had a significant impact on the backgammon community.
For example, on the opening play, the conventional wisdom was that given a roll of 2-1, 4-1, or 5-1, White should move a single checker from point 6 to point 5. Known as "slotting", this technique trades the risk of a hit for the opportunity to develop an aggressive position. TD-Gammon found that the more conservative play of 24-23 was superior. Tournament players began experimenting with TD-Gammon's move, and found success. Within a few years, slotting had disappeared from tournament play (it's now reappearing for 2-1, though).
Backgammon expert Kit Woolsey found that TD-Gammon's positional judgement, especially its weighing of risk against safety, was superior to his own or any human's.
TD-Gammon's excellent positional play was undercut by occasional poor endgame play. The endgame requires a more analytic approach, sometimes with extensive lookahead. TD-Gammon's limitation to two-ply lookahead put a ceiling on what it could achieve in this part of the game. TD-Gammon's strengths and weaknesses were the opposite of symbolic artificial intelligence programs and most computer software in general: it was good at matters that require an intuitive "feel", but bad at systematic analysis.